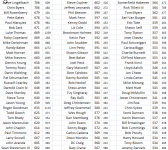
I think you missed mine.
All those ratings should be considered to have error bars.
And you know better than I how big those error bars should be.
Yes. The next paragraph is technical, so skip it if you're allergic or don't care
We maximize the Log-Likelihood function to get the ratings. The matrix of second derivatives of the
log-likelihood function--formulas for which we have derived--is called the
Fisher Information Matrix. Diagonal elements of the inverse of the Fisher Information matrix are--according to the
Cramer Rao Inequality lower bounds to the variance--i.e, error bars. Off diagonal elements of the Fisher information inverse also tell us the covariance--the degree to which one player's rating is coupled to that of another. So yes, we know how to get error bars and how to get estimates of error bars.
Anything within them should be classified as 'too close to call'. Pretending to have knowledge that you don't in fact have, is only going to lead to people mistrusting you, and your rating system. [...].
We don't actually "call" matches. Suppose two players are rated 766 and 750. The 16-point gap says the 766 will 60% of the time win a race to 11. That means 40% of the time the 750 will win. This uncertainty in the outcome of an individual match is there even when we are certain of the ratings.
When we are uncertain of the ratings (the real rating gap might instead of being 16 points be 26 points or 6 points or might even go the other way), then we have uncertainty not only in the outcome like above but in the 60% itself. Regardless, 60/40 is still our best guess for these players, and if we are going to devise a test to figure out whether our ordering of players is superior or inferior to some other ordering in predicting match outcomes, this is what we should use. Yes some of the matches are going to be coin flips--no harm no foul on that.
I appreciate the support from some of you, and I do think we often talk past one another, but I actually don't take exception to what Mr. Corwyn_8 says.
A lot of people look our efforts and both don't know us very well and don't understand the details--understandable on both counts. When they see a list of players, either pros or players from their area, and a player rating pops out as not passing their smell test a red flag goes up. Also understandable. We live in a world with a lot of people out there making unsupported claims.
We hope, slowly, to gain people's trust. And we think we will. We have seen lot's of red flags being waived when we put stuff out there
Johnny Archer is no longer a top US player
Jiaging Wu should be nowhere near the Ko's & crew
Justin Bergman is not a top world-class player
Efren shouldn't be invited to Bigfoot
and so forth...
I think our assessment has and will continue to be vindicated.
For now, for me to claim without even knowing who the 32 players are that Fargo Ratings will doing a better job guessing match outcomes than WPA rankings, I'd say that's a pretty bold statement...