Does time factor into the rating calculation or robustness at all?
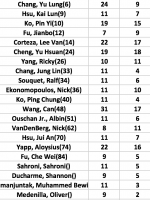
For example Wu, Jiaqing is world number one. But we have a lot more recent results from other top players Shane, Dennis, Alex, etc...
I'd think that old results (a few years or older) would become less weighted compared to recent results. Or perhaps just a decay in robustness. I guess I'm not sure if the system is suppose to be defining the relative skill over a certain period of time? or forever? It would seem silly to enter results from more than 10 years ago as players get old and also inactive over time.
Some sort of time factor in this system
https://en.wikipedia.org/wiki/Glicko_rating_system
For example Wu, Jiaqing is world number one. But we have a lot more recent results from other top players Shane, Dennis, Alex, etc...
I'd think that old results (a few years or older) would become less weighted compared to recent results. Or perhaps just a decay in robustness. I guess I'm not sure if the system is suppose to be defining the relative skill over a certain period of time? or forever? It would seem silly to enter results from more than 10 years ago as players get old and also inactive over time.
Some sort of time factor in this system
https://en.wikipedia.org/wiki/Glicko_rating_system